Winners & Losers in the DeepSeek Era
In every breakthrough, when new facts emerge, there are winners and losers. In an era of DeepSeek, who wins and loses?

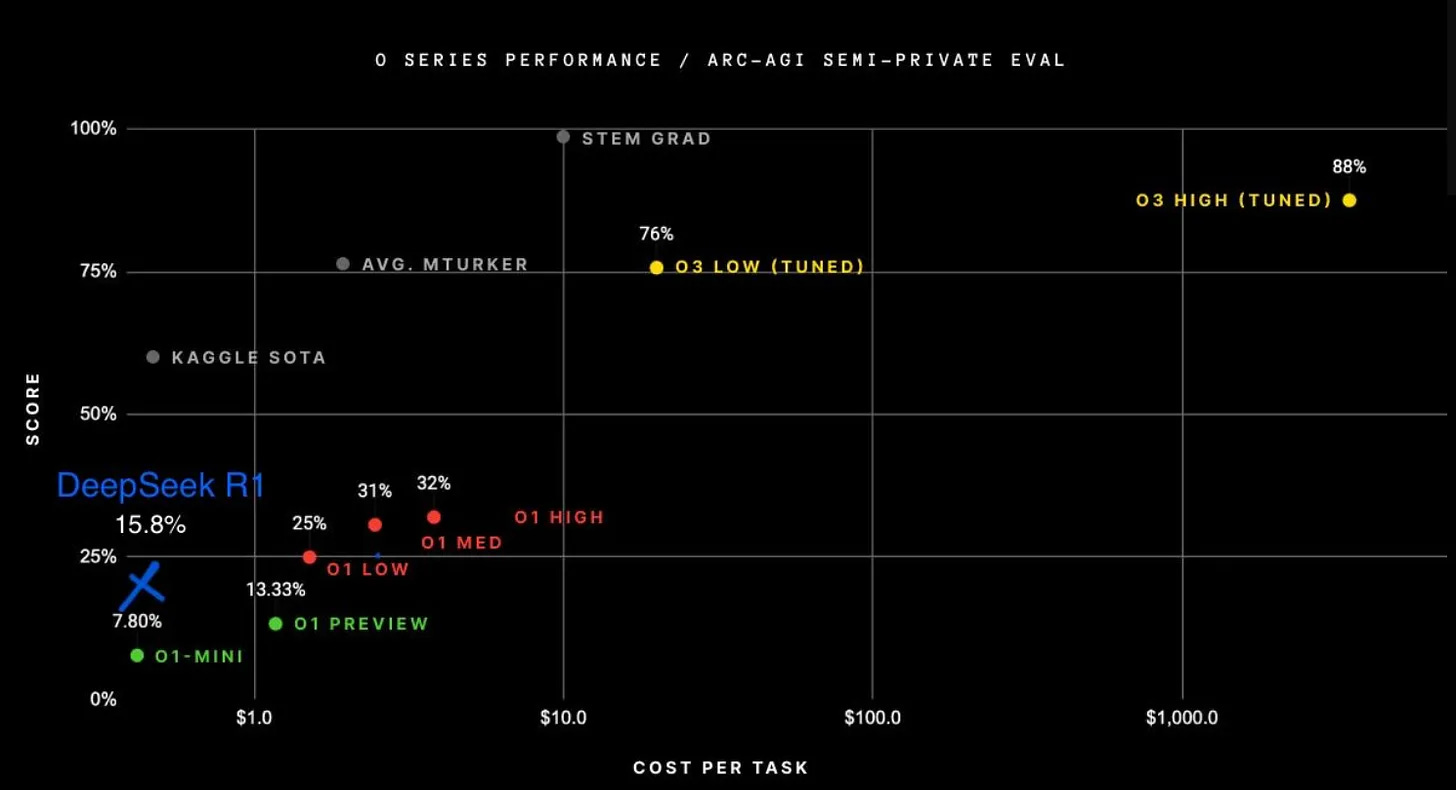
DeekSeep r1 represents a significant leap in AI – bringing an order of magnitude improvement in cost efficiency and accessibility at frontier AI performance. It’s a fork in history in AI. But, it likely could only be built now, not a year or two ago, given its extensive reliance on prior investments and distillations from existing leading frontier models.
Let’s remind ourselves what makes DeepSeek unique:
DeepSeek r1 Overview:
Cost Efficiency: r1 is 93% cheaper to use per API call compared to o1, making it highly cost-effective.
Local Deployment: Can be run locally on a high-end workstation with 37 GB of RAM (1 GB per 1B active parameters in FP8).
Performance: No rate limits observed, and batching/compute optimization further reduces costs and increases token speed.
Geopolitical Context: Released shortly after "Stargate," hinting at geopolitical dynamics in AI development.
Real:
Market Success: #1 download in its App Store category, surpassing ChatGPT, Gemini, and Claude.
Quality: Comparable to o1 in quality but lags behind o3.
Algorithmic Breakthroughs: Innovations like FP8 training, MLA, and multi-token prediction significantly improved efficiency in training and inference.
Training Cost: Verified $6M training cost (compute only), though this figure is misleading without context.
Hardware Innovation: Novel architecture using PCI-Express for scaling.

Nuance:
Hidden Costs: The $6M figure excludes prior research, ablation experiments, and access to large GPU clusters (e.g., 10k A100s). Real cost is much higher for labs without existing infrastructure.
Distillation Reliance: Likely relied on distillation from GPT-4o and o1, raising questions about export restrictions on GPUs versus access to advanced models.
Geopolitical Implications: Highlights the inefficacy of restricting GPU exports while allowing access to distilled models, undermining the purpose of such restrictions.
Short & Long Term Winners & Losers
Short Term
Losers:
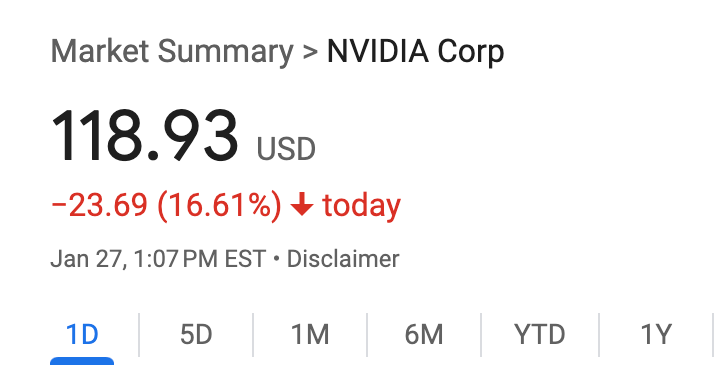
Nvidia: Market scare due to potential decreased demand for high-end GPUs for training.
OpenAI / Anthropic / Google: Pressure to reduce costs or accelerate innovation to compete with more efficient models.
Stargate: $500B looks a bit out of touch now
Cloud Providers (AWS, Azure, GCP): Customers could Immediately demand for the hyperscalers to offer DeepSeek or similarly cost-efficient + performant models.
Overall Training Capex: This trend is not favorable for near-term capital expenditure in AI training or the "power" theme.
Winners:
AI at large: The research in AI just accelerated by 2 - 3 years.
Open Source First: Gains from community-driven innovation and model adaptation.
New Model Developers: Easier entry with less need for extensive hardware.
Coding Agents & Assistants: Efficiency of complex tasks enables faster, cheaper handling of complex coding tasks, boosting productivity through parallel computing.
Academic Researchers: More accessible high-performance AI models for research.
Investors in open source AI companies: Potential high returns from investments in cost-effective AI solutions.
Benefit for AI Users: Companies that use AI (software, internet, etc.) stand to gain significantly.
Long Term
Losers:
China: Lack of comparative AI data center infrastructure will throttle their ability to maximize and keep up.
OpenAI: Possible decline in proprietary model value if open-source alternatives thrive.
Traditional Software Companies: Risk of losing market share to AI-enabled competitors at a more accelerated pace.
Data Labeling Companies: As AI models become more efficient and require less labeled data for training, companies specializing in data annotation (e.g., Scale AI) could see reduced demand.
Winners:
ASI: We will get to ASI (super intelligence) much sooner than we anticipated.
US Dominance in AI: Leveraging US strengths in computing power, innovation, and infrastructure to more efficient and performant models will lead to AI escape velocity.
Enterprises: More AI, everywhere.
Explosion of New Use Cases and Specialized Models: Innovation in sector-specific applications.
Nvidia: Long-term demand for inference GPUs, new markets in hardware optimization.
Healthcare: AI-driven improvements in complex areas such as Healthcare for diagnostics, treatment, and efficiency.
Additional Consideration:
Capacity Utilization: Even though DeepSeek and similar technologies make model training more efficient, the trend of models growing in size and complexity means we are likely to continue maxing out available computing capacity. Just two years ago, models were significantly less capable than today's, yet we've seen no slowdown in the demand for computational resources. This suggests that while efficiency helps, the hunger for more advanced, larger models will keep pushing the limits of what's available, potentially leading to new cycles of infrastructure investment or innovative approaches to capacity management.
Nvidia (Short-Term Loser): While Nvidia may face short-term uncertainty, its dominance in GPU manufacturing and its ability to pivot to inference-focused hardware could make it a long-term winner.
Cloud Providers: While they may face short-term pressure, hyperscalers like AWS, Azure, and GCP could adapt by offering DeepSeek-like models as part of their services, turning a potential threat into an opportunity.