AI’s Next $Trillion Frontier: Memory
The limiting factor is no longer how many operations a chip can perform. It is how quickly data can move to and from those compute units — and how much energy it costs to do so.

For most of modern computing, performance scaled with compute.
We moved from CPU-bound systems to GPU acceleration. We optimized arithmetic throughput. We counted FLOPs. We built larger clusters and assumed the bottleneck would remain math.
That era is ending.
AI systems are shifting from compute-bound to memory-bound. The limiting factor is no longer how many operations a chip can perform. It is how quickly data can move to and from those compute units — and how much energy it costs to do so.
Recent SemiAnalysis work makes this explicit. Even when raw silicon is comparable, rack-based architecture alone can drive up to ~9x differences in effective bandwidth depending on topology and coupling. Performance is increasingly determined by how well we can move the data, not just compute it.
Nvidia CEO Jensen Huang put it bluntly: “Without the HBM memory, there is no AI supercomputer.”

This is not a chip problem.
It is a memory problem.
The Science of HBM — and Its Limits
High Bandwidth Memory exists because traditional DRAM could not keep pace with accelerators.
DRAM is a high-density, cost-efficient memory technology that stores data in capacitors requiring periodic refresh, making it ideal for large-capacity systems like HBM in AI GPUs.
SRAM is a low-latency, flip-flop-based memory technology that does not require refresh, making it significantly faster but less dense and more expensive than DRAM, and therefore best suited for on-chip caches and compute-adjacent buffers.
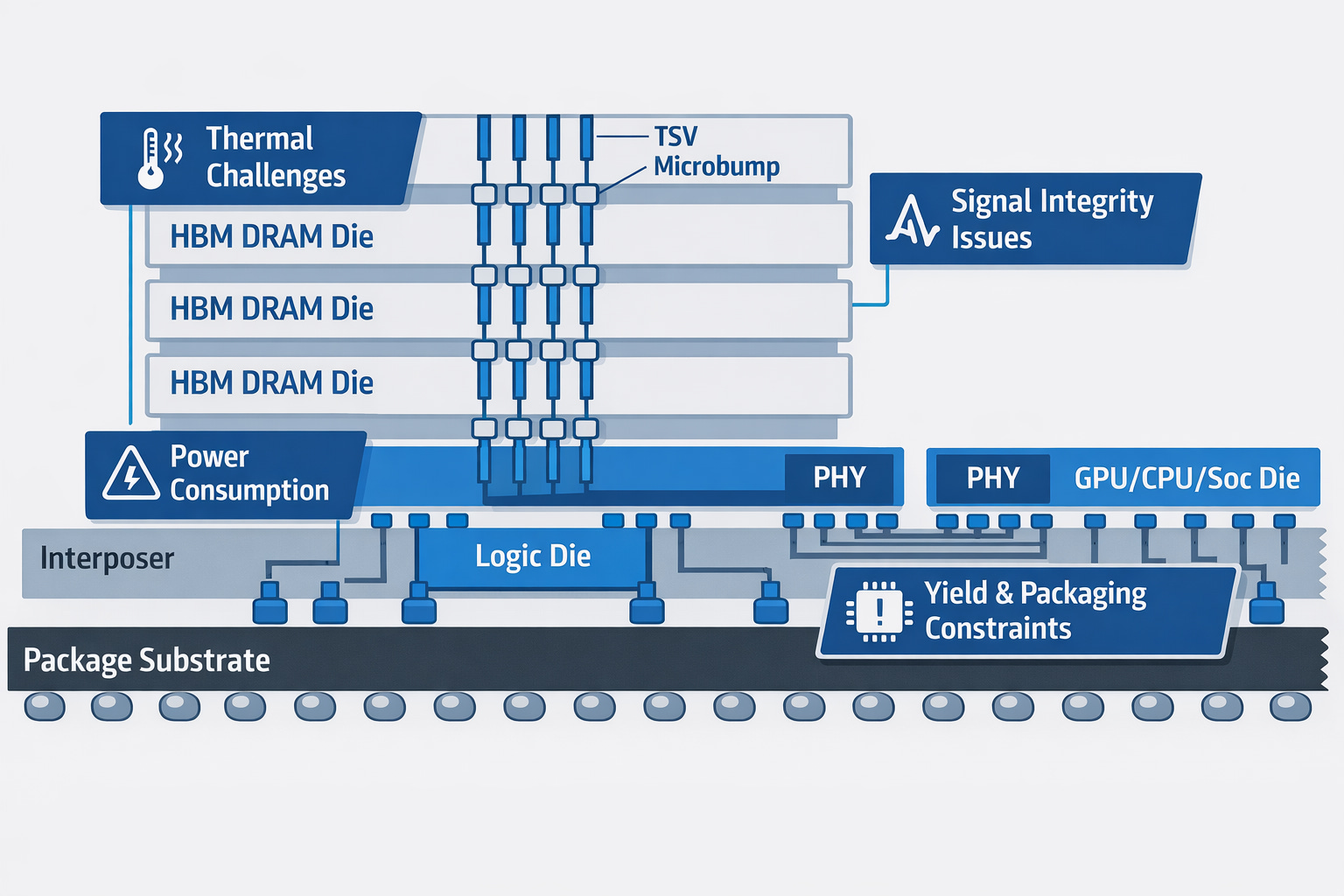
By stacking DRAM dies vertically with through-silicon vias and dramatically widening the data bus, HBM increases aggregate bandwidth while reducing energy per bit moved. It trades frequency for width and distance for proximity.
Without HBM, modern AI systems would stall.
But HBM is an evolutionary solution to a structural constraint.
As GPUs scale from tens to hundreds of billions of parameters — and from single-node systems to rack-scale integration — pressure on bandwidth-per-watt compounds. Compute accelerates. Data movement increasingly dominates system-level energy.
The memory wall has not disappeared.
It has been deferred.
The Constraint Is Compounding
Three bottlenecks are converging.
Bandwidth density. Even with HBM, large models saturate memory channels. More stacks mean more packaging complexity and tighter yield constraints.
Energy per bit. At scale, moving data often consumes more energy than computing on it. In dense racks, this becomes a thermal limit.
System integration. Performance deltas now come from topology, interconnect, and memory coupling — not just transistor counts.
SemiAnalysis shows that recent generation-to-generation systems have delivered 10x+ improvements in performance-per-dollar for inference in certain configurations. Those gains accelerate deployment. They do not relieve memory pressure. They amplify it.
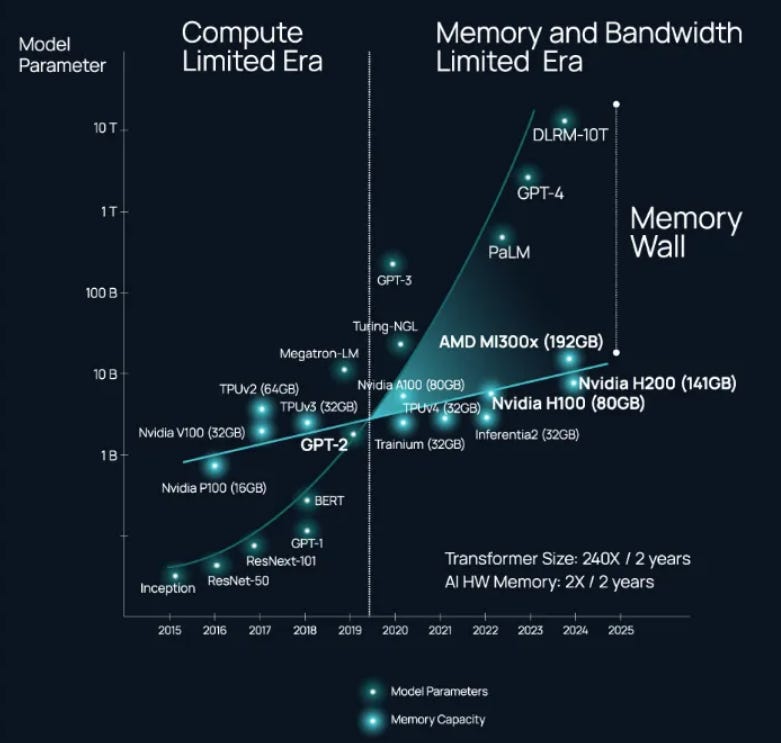
Transformer sizes have grown 240x in 2 years, while HBM 2x in year years. Compute scaling increases memory stress.
The faster we push AI, the harder the wall pushes back.
Why This Is Hard
Reinventing memory is difficult because physics pushes back. Higher bandwidth degrades signal integrity, stacked architectures amplify thermal density, and energy per bit rises with distance — all while packaging complexity erodes yield.
Memory must optimize density, bandwidth, latency, energy, manufacturability, and cost simultaneously. Improvements in one dimension often degrade another.
This is why most attempts at “better DRAM” fail.
The bar is not novelty.
It is physics plus yield plus ecosystem compatibility.
Memory Scarcity Not By Accident.
This is no longer theoretical.
Driven by AI demand, 64GB DDR5 pricing has surged from roughly $150 to $500 in under two months. Industry discussions already point to 25–30% DRAM contract price increases into late 2025. HBM capacity remains constrained and concentrated.
“Buy more GPUs” is no longer the only scaling constraint.
Memory pricing and supply are becoming strategic variables. Three suppliers — Samsung, SK Hynix, and Micron — control roughly 95% of global DRAM production. As AI demand explodes, they are rationally reallocating wafer capacity toward ultra-profitable HBM, which consumes more advanced process steps and significantly more packaging complexity per gigabyte than commodity DDR.
The incentive is clear: prioritize scarce capacity toward the highest-margin product, keep supply tight elsewhere, and let pricing follow.
In that world, memory scarcity is not an accident.
It is an equilibrium.
Nvidia’s HBM Hedge
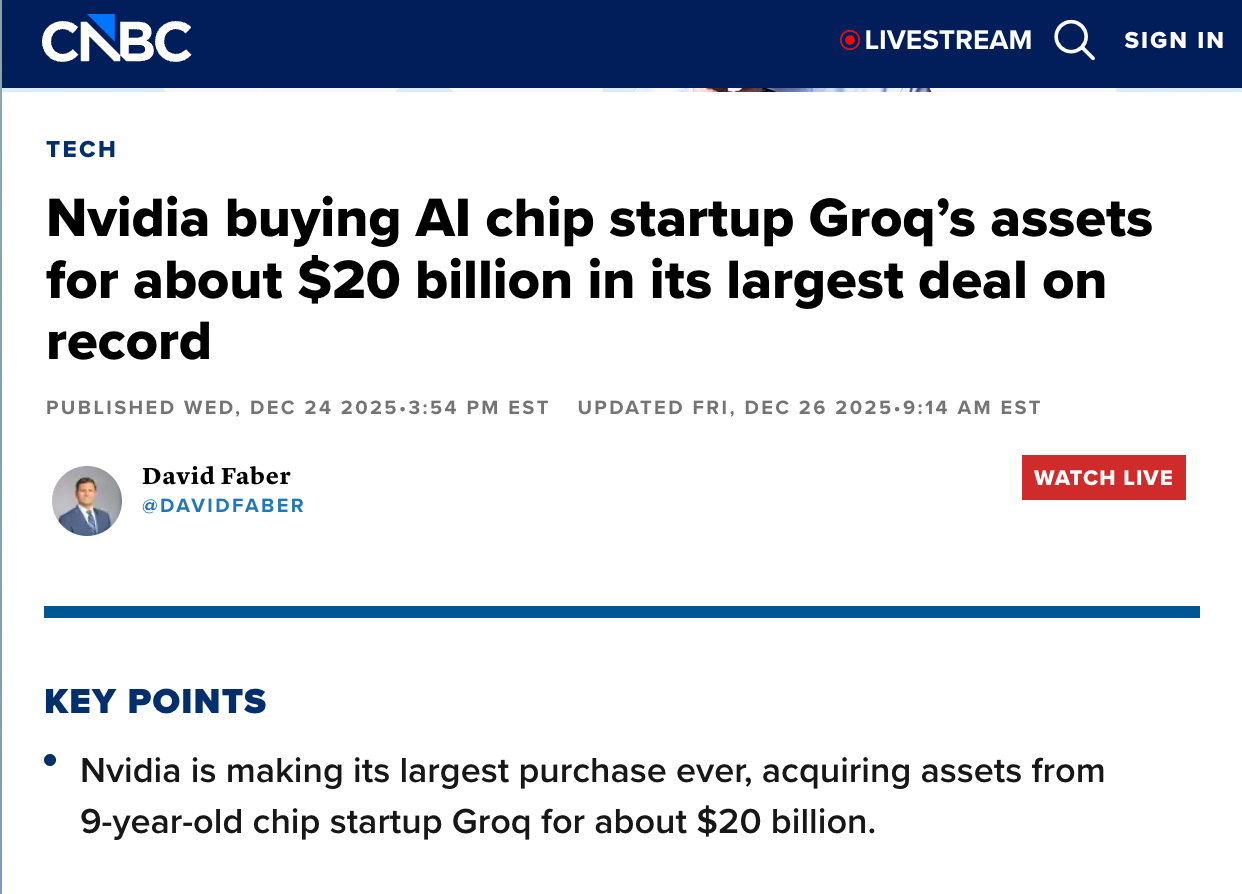
In that context, Nvidia’s $20B acquisition of Groq makes sense. Groq’s thesis is not faster arithmetic. It is reduced dependence on off-chip memory. By keeping more of the working set in on-chip SRAM and designing the compiler around locality, Groq reduces reliance on bandwidth-hungry external DRAM and HBM.
SRAM is limited and expensive. The advantage only materializes when the entire stack — hardware and compiler — is co-designed.
That is the point.
Nvidia effectively secured an inference path that is less HBM-hungry — a hedge against a future where memory supply and pricing determine who can scale inference.
Bending the Memory Curve
Beyond attempts at reducing HBM reliance, several serious approaches are attempting to bend the memory curve:
HBM4 and smarter base layers: The next version of HBM uses much wider connections and adds logic at the bottom of the memory stack, turning memory into something more programmable instead of just passive storage. They extend the current architecture, but they are still fundamentally constrained by stacking thermals, packaging yield, and DRAM scaling limits.
Better 3D stacking techniques: New bonding methods let memory chips stack more tightly and connect more efficiently, increasing bandwidth without driving power and heat out of control. Tighter stacking improves density, but heat removal, mechanical stress, and manufacturing yield become exponentially harder at scale.
Doing small bits of compute inside memory: Instead of constantly moving data back and forth, some designs perform limited operations directly inside the memory stack to cut unnecessary traffic. It reduces data movement for specific workloads, but general-purpose AI models are difficult to map cleanly onto limited in-memory compute blocks.
Splitting fast and slow memory more intelligently: Keep only the hottest data in ultra-fast HBM and push everything else to larger, slower pools so expensive bandwidth isn’t wasted. Tiering improves utilization, but it does not eliminate the need for massive high-bandwidth memory at the core of the system.
Replacing some copper links with optics: As electrical wiring becomes too power-hungry at high speeds, optical connections can move data using less energy over longer distances. Optics helps at scale-out boundaries, but it does not solve the dense, short-distance bandwidth and power constraints inside a package.
Fixing the packaging bottleneck: A lot of memory limits now come from how chips are physically connected and cooled, not from the memory cells themselves. Advanced substrates unlock routing density, but they remain complex, yield-sensitive, and dependent on concentrated manufacturing capacity.
Designing software around memory limits: Compilers and system software can schedule work and compress data in ways that reduce how often chips need to reach off-chip memory. Smarter compilers reduce traffic, but they cannot overcome the fundamental physical cost of moving bits off-chip.
Every one of these approaches attacks the same constraint: energy and bandwidth at scale. They optimize around the constraint, but they do not yet eliminate it.
Building the Next Great Memory Company
The next great HBM company will not win by being marginally better.
It will win by shifting system-level throughput.
Hyperscalers do not buy memory chips. They buy rack-level performance. If a new architecture does not materially improve tokens-per-watt at cluster scale, it will be absorbed by incumbent roadmaps.
To matter, a next-generation HBM architecture must:
Deliver step-function improvements in bandwidth-per-watt.
Improve rack-level throughput, not isolated memory benchmarks.
Integrate cleanly into existing accelerator and packaging ecosystems.
Scale under realistic yield and thermal constraints.
Offer roadmap depth that compounds advantage over generations.
Anything less will be incremental.
The Frontier Is Shifting
For the first decade of modern AI, progress was gated by algorithms.
Today, it is gated by data movement and energy.
When rack topology can drive ~9x differences in effective bandwidth, and performance-per-dollar can jump 10x generation-over-generation, it becomes clear that system-level integration — not raw silicon — is the competitive frontier.
Memory now sits at the center of that frontier.
HBM once reset the limits of accelerator design. The next breakthrough will do the same.
If you are building a next-generation memory architecture that materially shifts bandwidth-per-watt — or investing behind one — we should talk.
The frontier is no longer just software. It is physics.
And the next great AI infrastructure company will be built there.